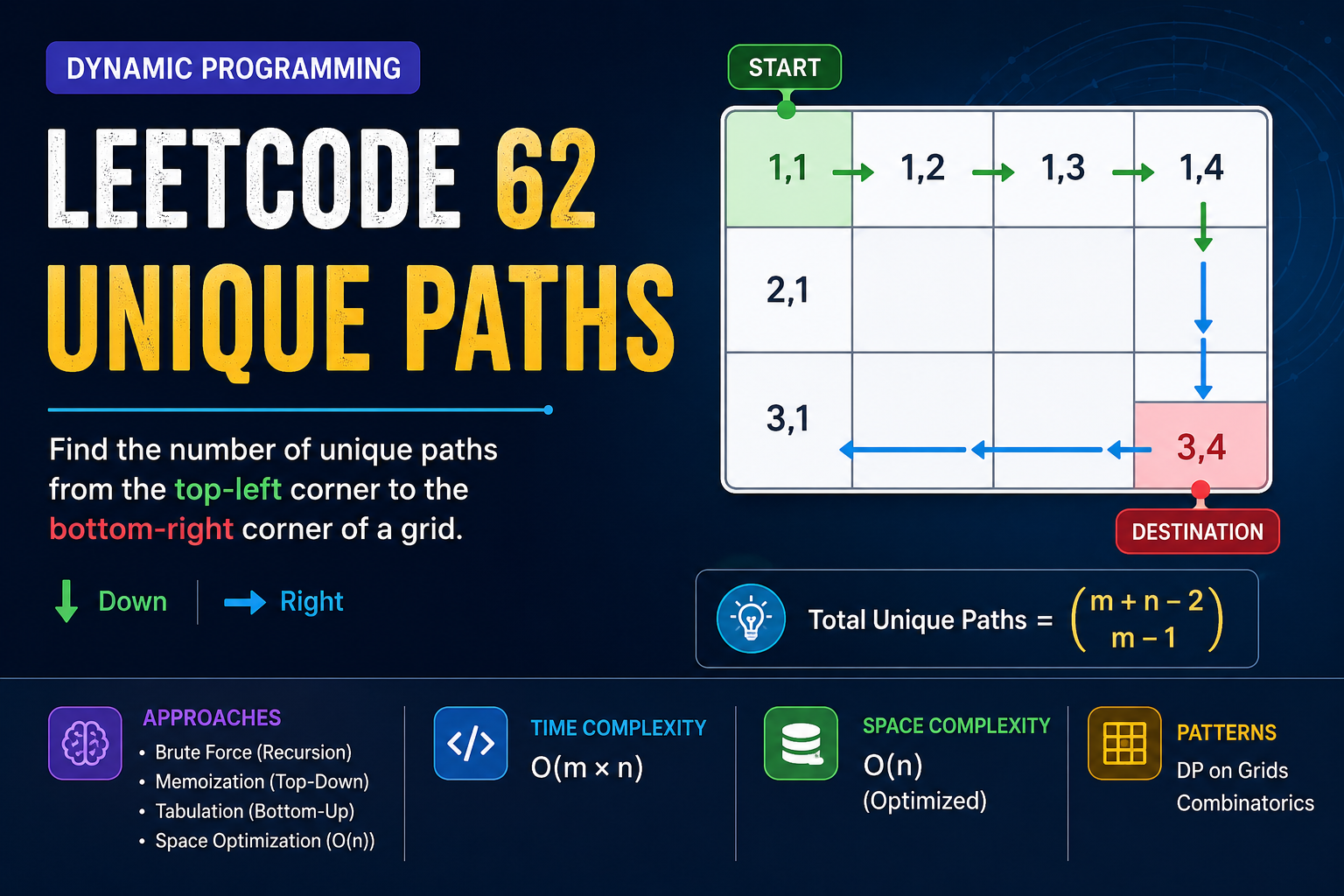
LeetCode 62: Unique Paths
Problem Statement
You are given an m × n grid. A robot starts at the top-left corner(0,0) and wants to reach the bottom-right corner(m-1,n-1).
The robot can only move in two directions:
- Right →
(i, j + 1) - Down ↓
(i + 1, j)
Your task is to find the total number of unique paths the robot can take to reach the destination.
Example 1
Input
m = 3, n = 7
Grid
m = 3, n = 7
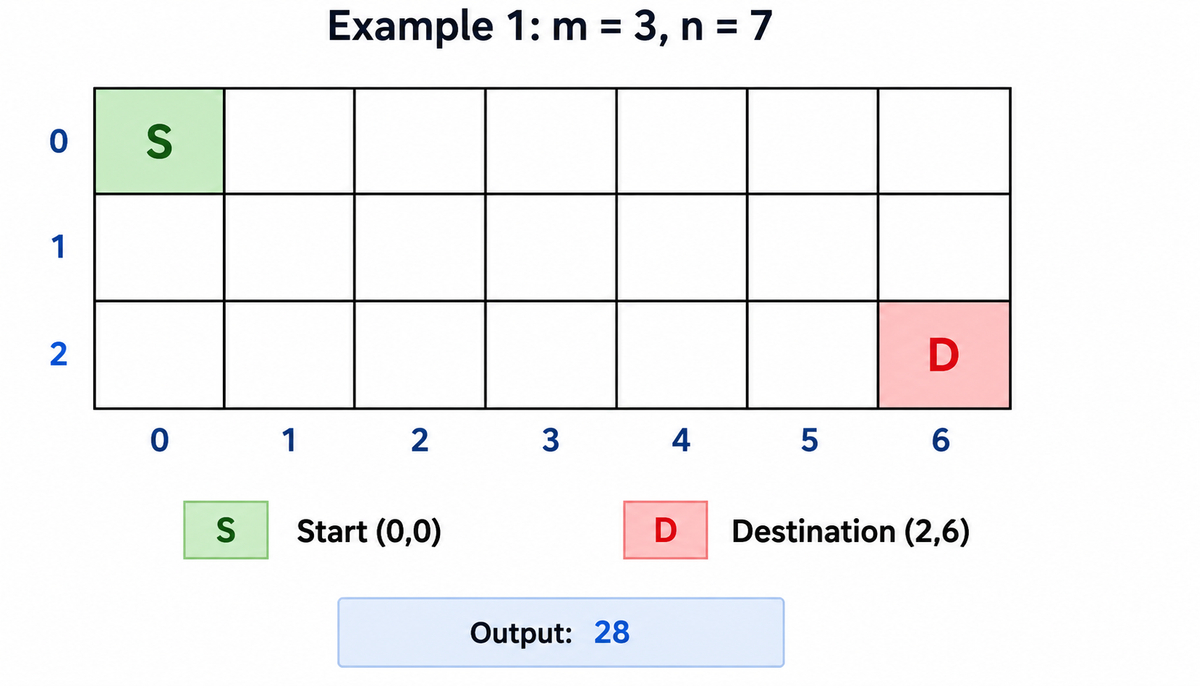
S = Start (0,0)
D = Destination (2,6)
S= StartD= Destination
Output
28
Explanation
To reach the destination, the robot must make:
o reach the destination, the robot must make:
2Down moves6Right moves
These moves can be arranged in different orders, producing 28 unique paths.
Brute Force Approach (Recursion)
The most straightforward way to solve the Grid Unique Paths problem is to explore all possible paths from the top-left corner (0,0) to the bottom-right corner (m-1,n-1).
At every cell, we have only two choices:
- Move Down
(i+1, j) - Move Right
(i, j+1)
We recursively try both possibilities and count the number of valid paths that reach the destination.
Intuition
Imagine standing at a cell in the grid. To reach the destination, you can either:
- Go one step down and count all paths from there.
- Go one step right and count all paths from there.
The total number of paths from the current cell is:
paths = paths_from_down + paths_from_right
Recursive Algorithm
- If we reach the destination cell, return
1because we found a valid path. - If we go outside the grid boundaries, return
0. - Recursively explore the down and right directions.
- Return the sum of both recursive calls.
C++ Code
class Solution {
public:
int solve(int i, int j, int m, int n) {
if (i == m - 1 && j == n - 1)
return 1;
if (i >= m || j >= n)
return 0;
int down = solve(i + 1, j, m, n);
int right = solve(i, j + 1, m, n);
return down + right;
}
int uniquePaths(int m, int n) {
return solve(0, 0, m, n);
}
};Dry Run
For m = 2 and n = 3:
Start (0,0)
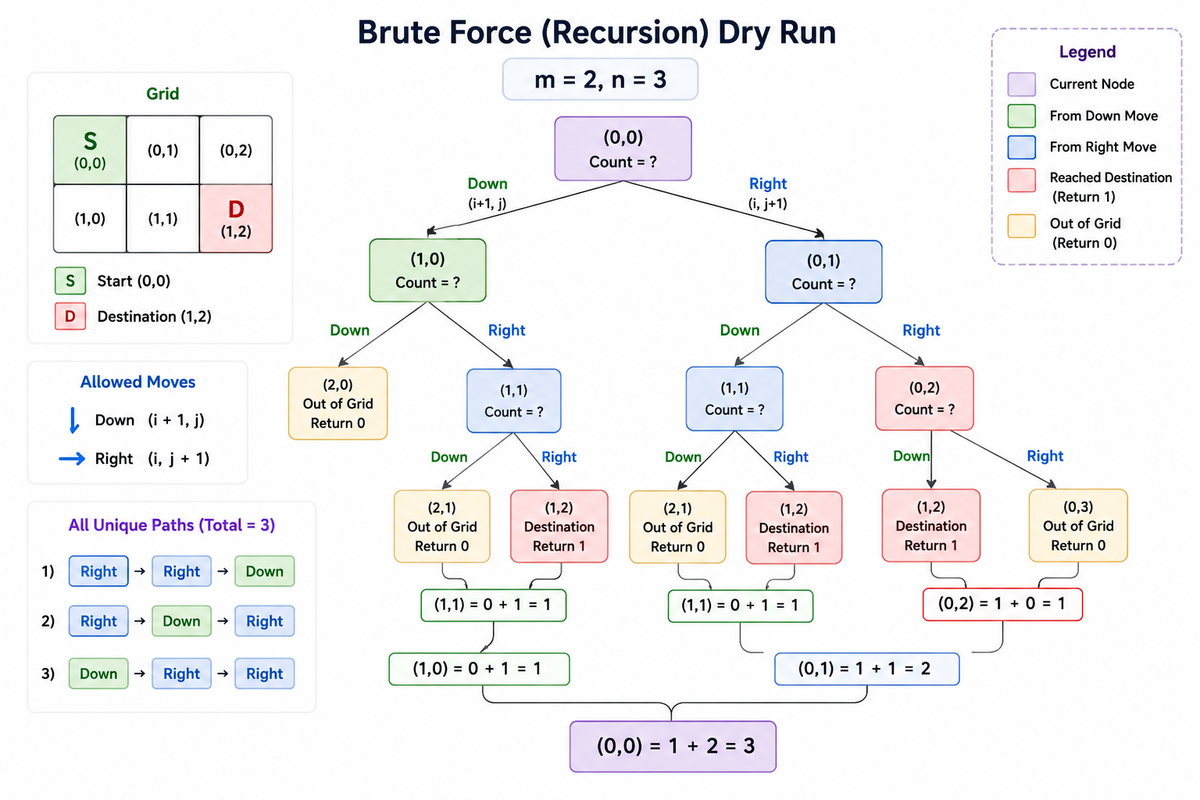
Valid paths:
- Right → Right → Down
- Right → Down → Right
- Down → Right → Right
Answer = 3
Time Complexity
At each cell, we make two recursive calls.
Time Complexity: O(2^(m+n))
This is extremely inefficient because the same subproblems are solved repeatedly.
Space Complexity
The maximum recursion depth is equal to the path length.
Space Complexity: O(m + n)
note:you are not using space but recursion used recursion stack space thats why o(m+n)
Limitation of Brute Force
Many states are recalculated multiple times.
For example, the state (1,1) can be reached from both:
(0,1)(1,0)
This leads to a large number of redundant computations, making the brute force solution impractical for larger grids.
To eliminate these repeated calculations, we use Dynamic Programming (Memoization) in the next approach.
Approach 2: Memoization (Top-Down DP)
Intuition
In the brute force solution, we repeatedly solve the same subproblems.
Consider the recursion tree for m = 2, n = 3:
solve(0,0)
├── solve(1,0)
│ └── solve(1,1)
└── solve(0,1)
└── solve(1,1)
Notice that:
solve(1,1)
is computed twice.
For larger grids, the same states are recalculated hundreds or even thousands of times, causing the exponential time complexity.
Idea
Store the answer for every state (i, j) the first time it is computed.
If we encounter the same state again:
- Return the stored value.
- Avoid recomputation.
This technique is called Memoization.
DP State
Let:
dp[i][j]
represent the number of unique paths from cell (i,j) to the destination.
Recursive Relation
From any cell:
dp[i][j] = solve(i + 1, j) + solve(i, j + 1)because we can move:
- Down
- Right
Algorithm
- Create a DP array initialized with
-1. - If destination is reached, return
1. - If outside the grid, return
0. - If the answer is already stored in
dp[i][j], return it. - Otherwise calculate and store the answer.
C++ Code
class Solution {
public:
int solve(int i, int j, int m, int n,
vector<vector<int>>& dp) {
if (i == m - 1 && j == n - 1)
return 1;
if (i >= m || j >= n)
return 0;
if (dp[i][j] != -1)
return dp[i][j];
int down = solve(i + 1, j, m, n, dp);
int right = solve(i, j + 1, m, n, dp);
return dp[i][j] = down + right;
}
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector<int>(n, -1));
return solve(0, 0, m, n, dp);
}
};Dry Run
For:
m = 2, n = 3
Initially:
dp =
[
[-1, -1, -1],
[-1, -1, -1]
]
After computation:
dp =
[
[3, 2, -1],
[1, 1, -1]
]
Explanation:
dp[1][1] = 1
dp[1][0] = 1
dp[0][1] = 2
dp[0][0] = 3
Answer = 3
Time Complexity
Each state (i,j) is computed only once.
Time Complexity: O(m × n)
Space Complexity
DP Array : O(m × n)
Recursion Stack: O(m + n)
Total Space: O(m × n)
Why Memoization is Better?
Approach Time Complexity
Brute Force O(2^(m+n))
Memoization O(m × n)
Memoization eliminates repeated calculations by storing previously computed results, reducing the complexity from exponential to polynomial.
Approach 3: Tabulation (Bottom-Up DP)
Intuition
In Memoization, we solve subproblems recursively and store their answers.
Can we avoid recursion altogether?
Yes!
the primary reason is to choose this is to avoid recursion stack space
In interviews memoisation approach is enough ,however it is recommended to learn tabulation ,so you could impress the interviewer by telling an additional approach
Instead of starting from the top and going down recursively, we can start from the destination and build the solution bottom-up using a DP table.
This approach is called Tabulation.
Key Observation
For any cell (i,j):
dp[i][j] = dp[i+1][j] + dp[i][j+1]
Why?
Because from the current cell, we can move:
- Down
- Right
So the total number of paths is the sum of paths from those two cells.
Base Case
The destination cell has exactly one path to itself.
dp[m-1][n-1] = 1
For example:
m = 2, n = 3
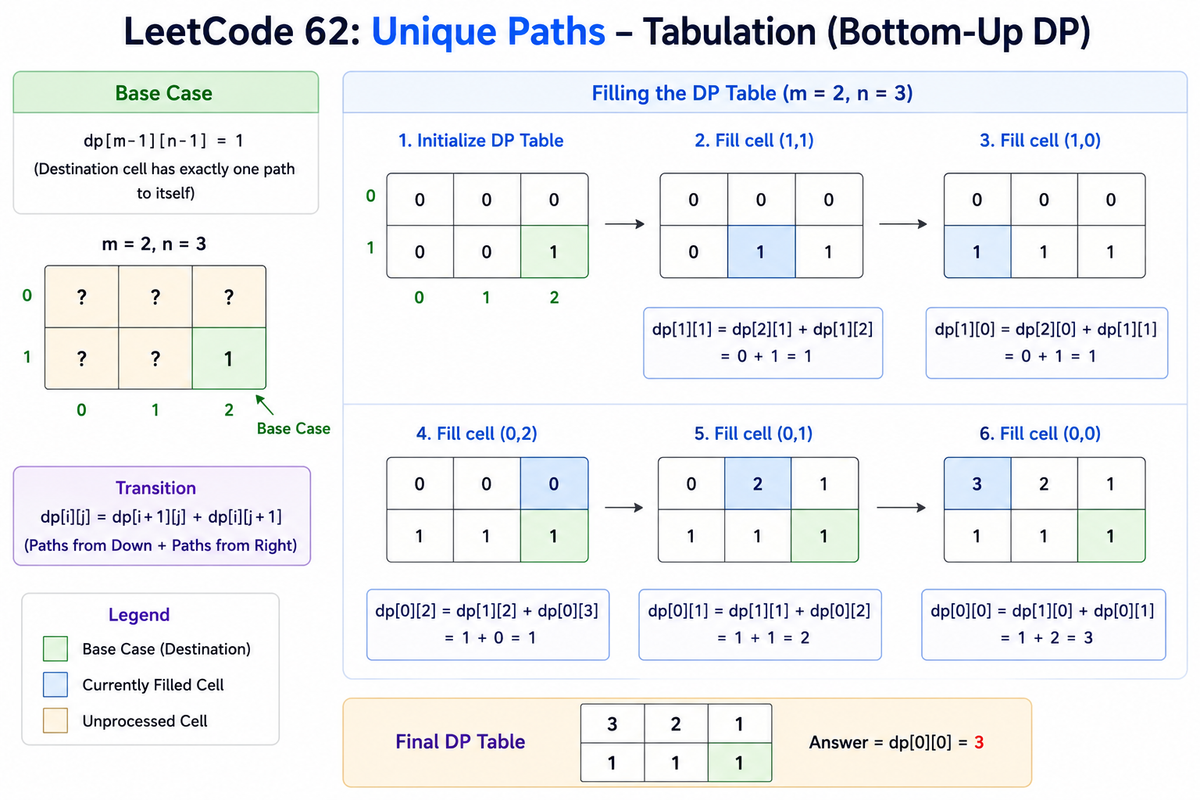
the above image shows how to fill out the dp table step by step in tabulation
Algorithm
- Create an
m × nDP table. - Set destination cell to
1. - Traverse from bottom-right to top-left.
- For each cell:
- Add paths from below.
- Add paths from the right.
5. Return dp[0][0].
C++ Code
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector<int>(n, 0));
for(int i = 0; i < m; i++) {
for(int j = 0; j < n; j++) {
if(i == 0 && j == 0) {
dp[i][j] = 1;
continue;
}
int up = 0;
int left = 0;
if(i > 0)
up = dp[i - 1][j];
if(j > 0)
left = dp[i][j - 1];
dp[i][j] = up + left;
}
}
return dp[m - 1][n - 1];
}
};Time Complexity
Each cell is visited exactly once.
Time Complexity: O(m × n)
Space Complexity
Space Complexity: O(m × n)
Why Tabulation?
Compared to Memoization:
- No recursion overhead.
- No recursion stack space.
- Often faster in practice.
- Easier to optimize further.
This observation leads to the Space Optimized DP solution, where we reduce the space complexity from O(m × n) to O(n).
Now before going to next approach if you feel you learnt well till this you can stop because space optimisation is not asked in interviews ,however its useful for competetive programming. but i recommend you to learn though ,who knows may be the interviewer can go to extremes.
Approach 4: Space Optimization
Intuition
In the tabulation approach, we used a 2D DP array:
vector<vector<int>> dp(m, vector<int>(n, 0));
This requires:
O(m × n) space
However, if we observe the recurrence carefully:
dp[i][j] = dp[i-1][j] + dp[i][j-1]
To calculate the current cell, we only need:
- The value from the previous row (
dp[i-1][j]) - The value from the current row's previous column (
dp[i][j-1])
We do not need the entire DP table.
Therefore, instead of storing all rows, we can store only:
- Previous row →
prev - Current row →
curr
This reduces the space complexity from O(m × n) to O(n).
Visualizing the Optimization
Tabulation DP Table
For m = 3, n = 4:
1 1 1 1
1 2 3 4
1 3 6 10
While computing Row 2:
Previous Row
1 2 3 4
Current Row
1 ? ? ?
To calculate each cell in the current row, we only need:
up = previous row value
left = current row previous value
So keeping the entire DP table is unnecessary.
Algorithm
- Create a 1D array
prevof sizen. - Traverse row by row.
- For every row, create a temporary array
curr. - Calculate current values using:
up = prev[j]left = curr[j-1]
- After completing the row, assign:
prev = curr;
- Return the last cell.
Dry Run
Input
m = 2, n = 3
Initial State
prev = [0, 0, 0]
Row 0
curr = [1, 1, 1]
Update:
prev = [1, 1, 1]
Row 1
Cell (1,0)
up = 1
left = 0
curr[0] = 1
Cell (1,1)
up = 1
left = 1
curr[1] = 2
Cell (1,2)
up = 1
left = 2
curr[2] = 3
Current row:
curr = [1, 2, 3]
Update:
prev = [1, 2, 3]
Answer:
prev[2] = 3
C++ Code
class Solution {
public:
int uniquePaths(int m, int n) {
vector<int> prev(n, 0);
for(int i = 0; i < m; i++) {
vector<int> curr(n, 0);
for(int j = 0; j < n; j++) {
if(i == 0 && j == 0) {
curr[j] = 1;
continue;
}
int up = 0;
int left = 0;
if(i > 0)
up = prev[j];
if(j > 0)
left = curr[j - 1];
curr[j] = up + left;
}
prev = curr;
}
return prev[n - 1];
}
};
Time Complexity
O(m × n)
We still visit every cell once.
Space Complexity
O(n)
Only two 1D arrays of size n are used.
Why Space Optimization Works?
The tabulation solution only depends on:
Top Cell → Previous Row
Left Cell → Current Row
Since older rows are never used again, storing the entire m × n table is unnecessary.
Thus, we reduce:
Space: O(m × n) → O(n)
while keeping the same:
Time Complexity: O(m × n)
problem link:
video reference: