Problem Statement
Given a string s, find the length of the longest substring (contiguous sequence of characters) without repeating characters.
A substring is a contiguous sequence of characters within the string.
"Without repeating characters" means every character in that substring appears at most once.
Examples
Example 1
text
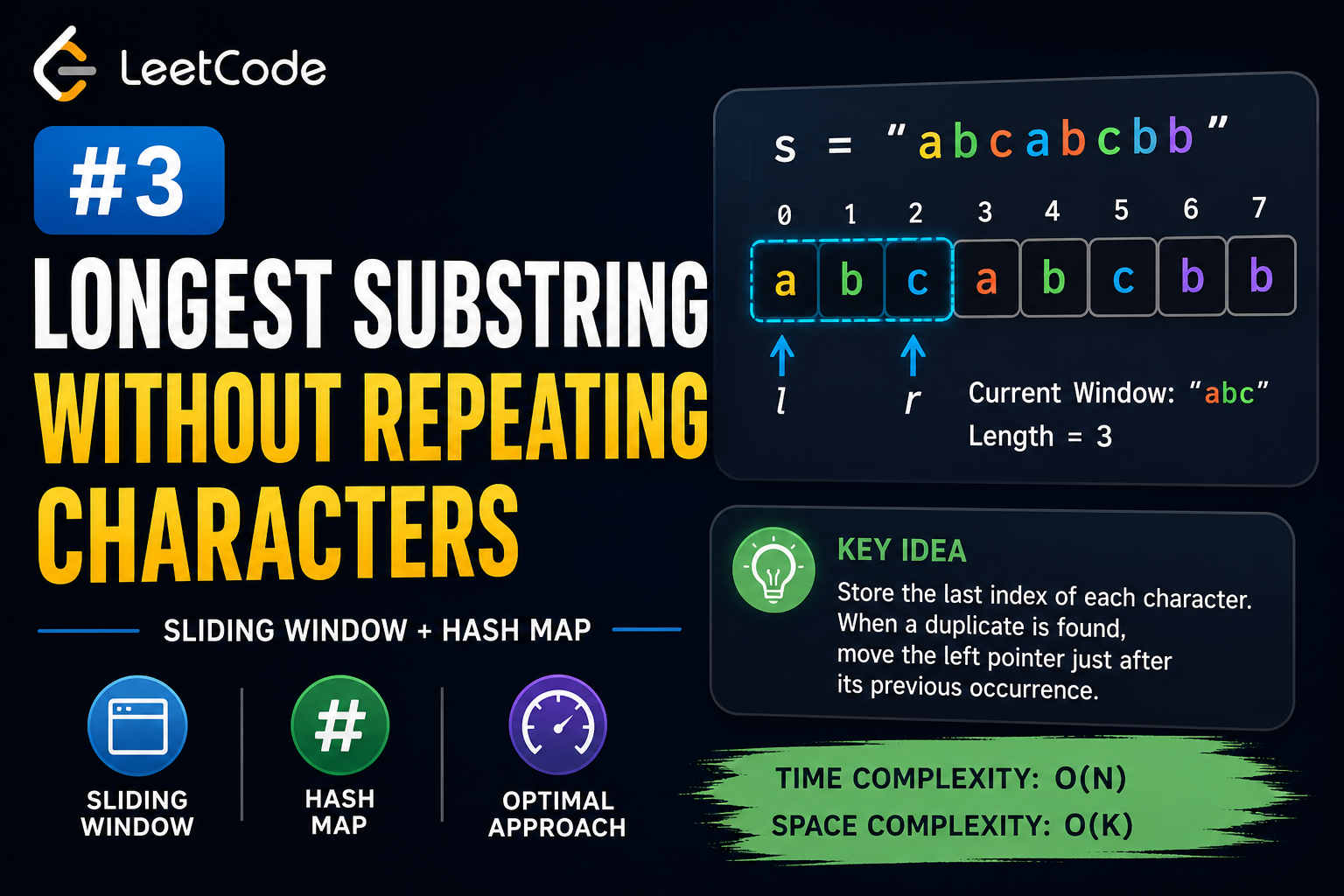
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.Other substrings like "bca", "cab" also have length 3, but none longer.
Example 2
text
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.All characters are the same, so the longest substring without repeats is just a single character.
Example 3
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke" or "kew", with the length of 3.Note: "pwke" is a subsequence, not a substring (not contiguous).
Example 4 (Edge Case)
Input: s = ""
Output: 0
Explanation: Empty string has no characters → length 0.Brute Force Approach – Intuition
The Simplest Thought Process
When you first see the problem, the most natural idea is:
"Let's check every possible substring and see if it has all unique characters. Then take the longest one."
This is like checking every possible window in the string – from the smallest (length 1) to the largest (the whole string).
Step-by-Step Intuition
Step 1: Generate all substrings
- A substring is defined by its start index
iand end indexj, where0 ≤ i ≤ j < n(n = string length) - For
"abc", substrings are:- Length 1:
"a","b","c" - Length 2:
"ab","bc" - Length 3:
"abc"
- Length 1:
Step 2: Check each substring for unique characters
- For a given substring, check if any character repeats
- How? Use a set or a boolean array (size 256 for ASCII)
- As you scan each character, if you see it again → substring invalid
Step 3: Track the maximum
- Keep a variable
max_lengththat updates whenever you find a valid substring longer than before
Step 4: Return the maximum
DRY RUN
String: "abcabcbb"
n = 8
Check substrings starting at index 0:
"a" ✓ (len=1) max=1
"ab" ✓ (len=2) max=2
"abc" ✓ (len=3) max=3
"abca" ✗ ('a' repeats)
stop for start=0
Start at index 1:
"b" ✓ (len=1)
"bc" ✓ (len=2)
"bca" ✓ (len=3) max stays 3
"bcab" ✗ ('b' repeats)
... continue for all starts ...
Final: max = 3c++ code
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int n = s.length();
int maxLength = 0;
for (int i = 0; i < n; i++) {
bool seen[256] = {false};
for (int j = i; j < n; j++) {
if (seen[s[j]]) {
break; // Found a repeat, stop extending
}
seen[s[j]] = true;
maxLength = max(maxLength, j - i + 1);
}
}
return maxLength;
}
};Complexity Analysis
Time Complexity: O(n³)
Why O(n³)? Here's the breakdown:
- Outer loop for start index
iruns O(n) times - Inner loop for end index
jruns O(n) times for each i - Checking uniqueness takes up to O(n) time per substring
- Total: O(n) × O(n) × O(n) = O(n³)
Space Complexity: O(min(n, m))
Where m is the character set size (for example, 26 for lowercase letters, 256 for ASCII characters). This space is used by the set when checking each substring.
Important note: For n = 100,000 (typical LeetCode constraint), O(n³) would take billions of operations, which is far too slow for practical use.
Optimal Approach - Sliding Window
Intuition
The brute force approach wastes a lot of time. When you find a repeating character, why start over from the next index? Instead, you can slide a window across the string and maintain a set of characters currently in the window.
Think of it like a window that grows and shrinks as needed. You have two pointers - left and right. The right pointer keeps moving forward, adding new characters. If you find a character that's already in the window, you move the left pointer forward until that duplicate character is removed from the window.
The key insight is that between any two repeating characters, the substring must start after the first occurrence of that character.
The Core Idea
Imagine you're scanning the string "abcabcbb" from left to right. You keep a window of characters with no repeats. As you see each new character:
- If it's not in your window, add it and expand the window
- If it is in your window, shrink the window from the left until that character is no longer in the window, then add the new character
The longest window size you ever see is your answer.
Algorithm
Step 1: Initialize left = 0, maxLength = 0, and an empty set (or hashmap) to store characters currently in the window.
Step 2: Loop right from 0 to n-1 (where n is string length):
- While
s[right]is already in the set, removes[left]from the set and incrementleft - Add
s[right]to the set - Update
maxLength = max(maxLength, right - left + 1)
Step 3: Return maxLength
Alternative using HashMap (store indices):
Instead of a set, use a hashmap to store the latest index of each character. When you find a repeat, jump left directly to max(left, previous_index + 1).
DRY RUN:
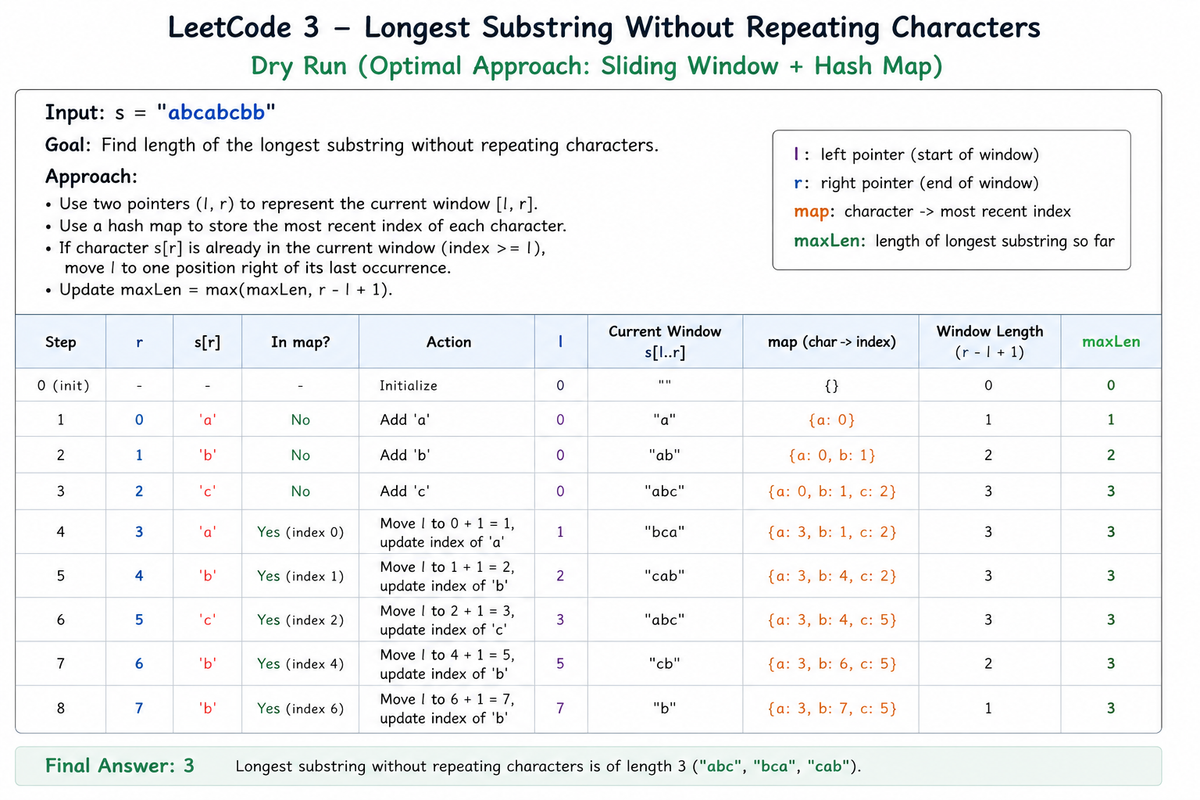
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<char, int> mp;
int l = 0;
int maxLen = 0;
for (int r = 0; r < s.size(); r++) {
if (mp.find(s[r]) != mp.end()) {
l = max(l, mp[s[r]] + 1);
}
mp[s[r]] = r;
maxLen = max(maxLen, r - l + 1);
}
return maxLen;
}
};Time Complexity: O(N)
Let N be the length of the string.
for (int r = 0; r < s.size(); r++)
The loop runs exactly N times.
Inside the loop:
mp.find(s[r])→ O(1) averagemp[s[r]] = r→ O(1) averagemax()→ O(1)
Also, the left pointer l never moves backward because of:
l = max(l, mp[s[r]] + 1);
So each character is processed only once.
Therefore:
Time Complexity = O(N)
Space Complexity: O(K)
The map stores the last index of each distinct character.
unordered_map<char, int> mp;
If:
s = "abcdef"
Map contains:
a -> 0b -> 1c -> 2d -> 3e -> 4f -> 5
So space depends on the number of unique characters K.
Space Complexity = O(K)
where:
K = number of distinct characters
For ASCII strings:
K ≤ 256
So many interviewers write:
Space Complexity = O(1)
because the character set size is fixed.
Interview-Friendly Summary
Time Complexity : O(N)
Space Complexity : O(K)
K = number of distinct characters.For ASCII character set, K ≤ 256, so space can be considered O(1).
This is the complexity expected for the optimal solution to LeetCode 3 – Longest Substring Without Repeating Characters
problem:
https://leetcode.com/problems/longest-substring-without-repeating-characters/
video reference:
Longest Substring Without Repeating Characters - Leetcode 3 - Python