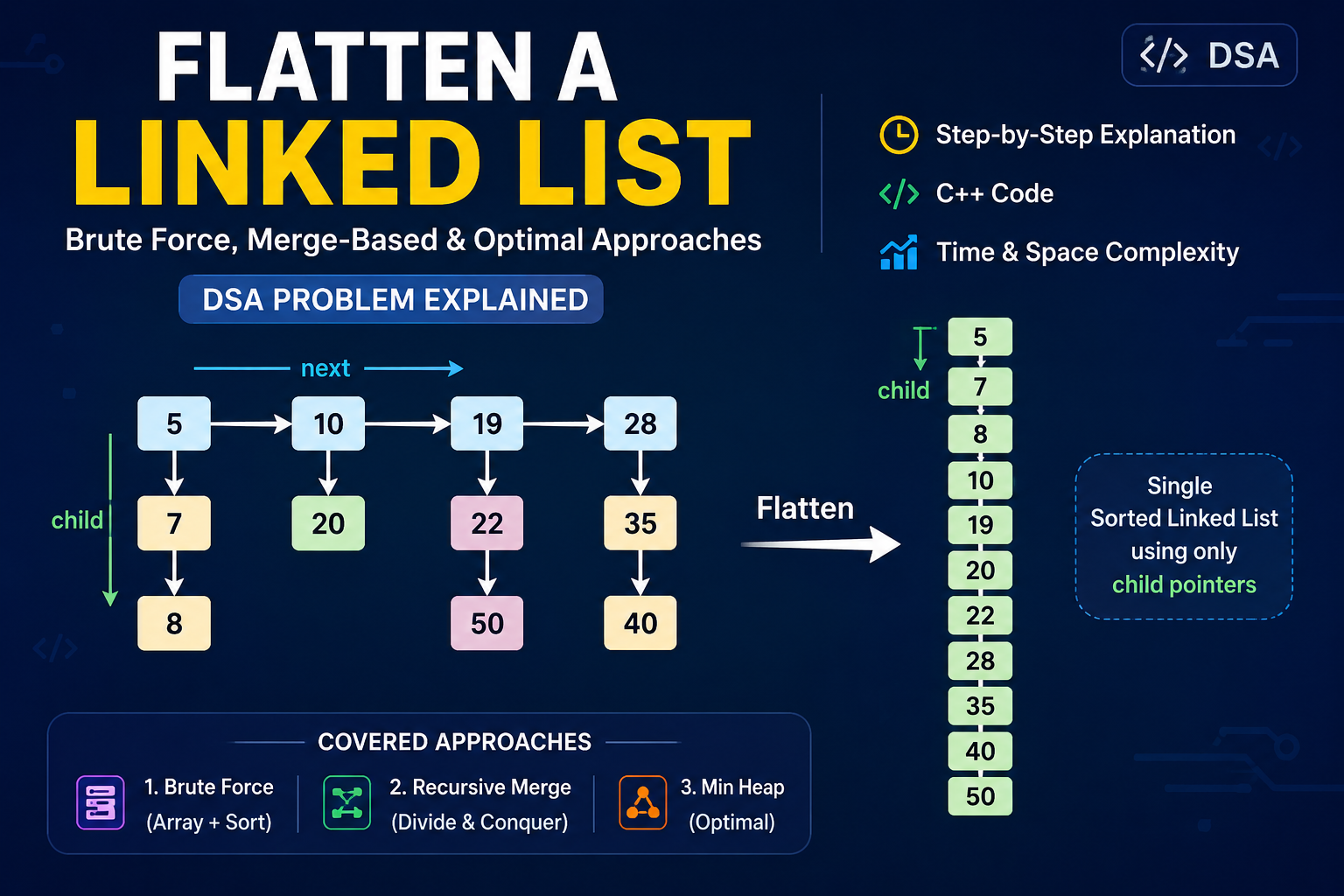
Understanding the Structure and Problem Statement
To tackle this problem, we must first look at the unique node structure. In a standard linked list, each node has a single next pointer. In this problem, every node contains two pointers:
next: Connects different sorted linked lists horizontally.child: Connects nodes vertically downwards, forming a sub-linked list.
Crucially, each vertical linked list is already sorted in ascending order. Our goal is to flatten this two-dimensional hierarchy into a single, completely sorted, one-dimensional linked list. By convention, the final flattened list should use the child pointer to link nodes together, while all next pointers are set to nullptr.
Problem Statement
Given a linked list where every node represents a sorted linked list horizontally via the next pointer, and each node has a sorted vertical linked list via the child pointer, flatten the linked list into a single, linearly sorted linked list using only the child pointer.
Example Input
Consider the following structure, where headers are linked via next and vertical columns are linked via child:
5 -> 10 -> 19 -> 28
| | | |
7 20 22 35
| | |
8 50 40
| |
30 45Expected Output
The output should be a single continuous chain linked exclusively by child pointers, sorted completely:
5 -> 7 -> 8 -> 10 -> 19 -> 20 -> 22 -> 28 -> 30 -> 35 -> 40 -> 45 -> 50The Core Intuition
The foundational challenge here is managing multiple sorted pathways simultaneously. Because each individual vertical column is already sorted, the problem is highly reminiscent of merging multiple sorted arrays or lists.
If we look at the vertical lists as individual streams of sorted data, our task boils down to consolidating these streams into a single sorted river. The structural transition looks like this:
- Input State: A 2D grid of nodes where
headpoints to the top-left item, moving horizontally vianextand vertically viachild. - Output State: A 1D sequence of nodes starting from the smallest global element, linked downward via
child, with all horizontalnextpointers cleared.
Approach 1: Brute Force (Array + Sort)
When confronted with a multi-layered pointer problem during an interview, it is always a safe strategy to start with a straightforward, brute-force approach. It demonstrates your problem-solving mindset and gives you a baseline complexity to optimize against.
Intuition
If the main complication is the two-dimensional nature of the pointers (next and child), we can eliminate that complexity entirely by extracting all the data. We can traverse every single node in the structure, collect their values into a dynamic array (or vector), sort that array using a standard sorting algorithm, and then construct a brand-new linked list from the sorted values.
Algorithm
- Create an empty dynamic array (e.g.,
std::vector<int>in C++ orArrayList<Integer>in Java). - Use a nested loop or iterative traversal:
- Start at the main
headnode. - While the current horizontal node is not null, traverse down its
childpointers. - Append the value of each node to the array.
- Move to the next horizontal node via the
nextpointer and repeat.
- Start at the main
- Sort the array in ascending order using a built-in sorting routine (like
std::sort). - Create a new dummy head node. Iterate through the sorted array, creating a new node for each value, and link them sequentially using the
childpointer. - Return the head of the newly created list.
Node* flattenLinkedList(Node* head) {
if (!head) return nullptr;
vector<int> arr;
// Collect all values
for (Node* h = head; h; h = h->next) {
for (Node* v = h; v; v = v->child) {
arr.push_back(v->data);
}
}
sort(arr.begin(), arr.end());
Node* newHead = new Node(arr[0]);
Node* cur = newHead;
for (int i = 1; i < arr.size(); i++) {
cur->child = new Node(arr[i]);
cur = cur->child;
}
return newHead;
}Step-by-Step Dry Run
Let's trace this with a scaled-down version of our example:
5 -> 10
| |
7 12- Traversal:
- Start at
5. Add5. Move to child7. Add7. - Move to next header
10. Add10. Move to child12. Add12. nodeValuesarray becomes:[5, 7, 10, 12].
- Start at
- Sorting: The array
[5, 7, 10, 12]is already sorted. - Rebuilding: A new list is allocated:
5 -> 7 -> 10 -> 12linked viachild.
Complexity Analysis
- Time Complexity: Let be the total number of nodes across the entire data structure. Traversing all nodes takes time. Sorting an array of size takes time. Rebuilding the list takes time. Thus, the total time complexity is dominated by the sorting step: .
- Space Complexity: We extract all node values into an array of size , which takes auxiliary space. Furthermore, constructing a brand-new linked list recreates nodes, adding another space overhead. Thus, the total space complexity is .
Advantages & Disadvantages
- Advantages: Extremely simple to understand, trivial to implement, and requires no intricate structural modifications or pointer manipulation.
- Disadvantages: High space complexity. It completely discards the valuable structural trait that individual vertical columns are already sorted. Recreating nodes also wastes memory allocations.
Approach 2: Recursive Merge Approach
To optimize, we must leverage the fact that every vertical list is pre-sorted. This insight allows us to frame the problem as a variation of the Merge Sort algorithm—specifically, the "Merge Two Sorted Lists" subproblem.
Intuition
Instead of trying to handle all columns at the same time, we can break the problem down recursively from right to left.
Imagine we have reached the final two columns on the far right. If we merge those two sorted columns into a single sorted column, we effectively reduce the problem size by one. We can repeat this process moving backward toward the left until the entire grid is consolidated into a single column.
The Role of the Dummy Node
When merging two sorted linked lists, tracking the head of the newly merged list can get messy because the smaller initial value could come from either list. To bypass tedious conditional pointer checks, we use a dummy node.
A dummy node acts as a temporary, fixed structural anchor. We append all sorted nodes directly to the dummy node's child pointer. Once the merge operation completes, the actual head of our merged list lives securely at dummyNode->child. This isolates the merge logic from head-tracking edge cases.
Why Use Only Child Pointers?
The problem requires the output to be a single linear list. Since the columns are structurally organized downward via child pointers, utilizing child pointers to link the final merged list keeps the memory alignment intuitive and satisfies the requirement. The horizontal next pointer of every node in the merged result is explicitly set to nullptr to prevent structural confusion.
Algorithm
- Base Case: If the
headisnullptror itsnextpointer isnullptr, return thehead(as there is nothing to merge). - Recursively move to the end of the horizontal list by calling
flatten(head->next). Let the returned head of this flattened remaining list be calledflattenedRemainder. - Merge the current vertical list (starting at
head) withflattenedRemainderusing a standard two-pointer sorted merge function. - In the merge function:
- Create a
dummynode. - Compare nodes from both lists, appending the smaller node to
dummy->child. - Ensure that for every attached node, the
nextpointer is explicitly set tonullptr.
- Create a
- Return
dummy->childas the head of the newly unified column.
C++ Code Implementation
class Solution {
public:
Node* merge(Node* a, Node* b) {
Node dummy(-1);
Node* tail = &dummy;
while (a && b) {
if (a->data < b->data) {
tail->child = a;
a = a->child;
} else {
tail->child = b;
b = b->child;
}
tail = tail->child;
tail->next = nullptr;
}
tail->child = a ? a : b;
return dummy.child;
}
Node* flattenLinkedList(Node* head) {
if (!head || !head->next)
return head;
head->next = flattenLinkedList(head->next);
return merge(head, head->next);
}
};Detailed Dry Run
Let’s walk through a dry run using three short columns:
L1: 5 L2: 10 L3: 19
| | |
7 20 22flattenRecursive(L1)is called.L1->nextis not null, so it callsflattenRecursive(L2).flattenRecursive(L2)is called.L2->nextis not null, so it callsflattenRecursive(L3).flattenRecursive(L3)hits the base case becauseL3->next == nullptr. It returnsL3(the list starting at19).- Execution returns to
flattenRecursive(L2). It setsL2->nextto the result ofL3. Now it callsmergeLists(L2, L3)to combine columns 2 and 3:- Compares
10and1910chosen. - Compares
20and1919chosen. - Compares
20and2220chosen. - Remaining
22attached. - Merged result (L2'):
10 -> 19 -> 20 -> 22. This is returned toL1.
- Compares
- Execution returns to
flattenRecursive(L1). It setsL1->nexttoL2'. It callsmergeLists(L1, L2'):- Combares
5with105chosen. - Compares
7with107chosen. - The rest of
L2'(10 -> 19 -> 20 -> 22) is attached.
- Combares
- The fully flattened, sorted list is successfully generated.
Complexity Analysis
- Time Complexity: Let be the number of horizontal elements (columns) and be the total number of nodes in the entire grid. Every time we merge two lists, we process their nodes linearly. In the worst-case scenario, we end up merging longer and longer lists repeatedly. The total number of operations scales proportionally to . If every column has a length of roughly , then , making the runtime .
- Space Complexity: auxiliary space. This space is consumed by the implicit recursion call stack, which goes levels deep down to the last column before unwinding.